
Représentation graphique
Histogrammes
Reprenons l'exemple des médecins en essayant d'améliorer le graphique. Pour cela, on va représenter sur un graphique en abscisse les différentes classes d'intervalle de gains et en ordonnée le pourcentage de personnes obtenant ces gains.
Si on ne prend aucune précaution, cela nous donne le graphique suivant, qui est bien évidemment faux.
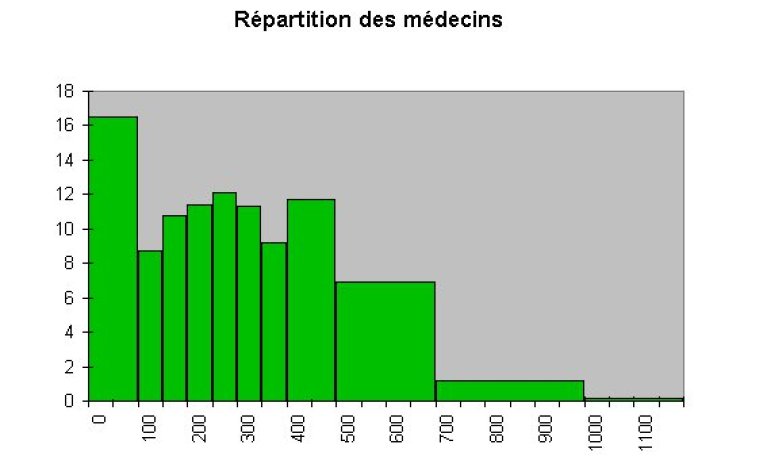
On se rend compte qu'il y a un problème d'échelle pour pouvoir comparer correctement les différentes classes.
Pour cela, il est nécessaire d'avoir la même amplitude (c'est à dire la même largeur d'intervalle) pour chaque classe.
On prend donc pour amplitude de base la plus petite amplitude des différentes classes.
Note: un tel choix repose sur notre objectif et l'usage que l'on veut faire des données. Un autre choix possible aurait été de choisir un autre intervalle, l'amplitude la plus large. Si ce choix sert mieux notre objectif, pourquoi ne pas l'utiliser ? De plus, chaque classe doit contenir suffisamment d'individus pour interpréter la hauteur du rectangle comme une approximation de la probabilité qu'une variable appartienne à la classe.
Dans l'exemple, on prendra donc comme amplitude de base 50, qui correspond à la largeur des classes [100, 150[, [150, 200[, [200, 250[, [250, 300[ et [350, 400[.
Il est donc nécessaire de corriger les autres classes.
Prenons par exemple la classe [500, 700[. On sait que 6, 95% des effectifs sont dans cette classe. Or, on doit transformer cette classe en des classes d'amplitude 50, soit [500, 550[, [550, 600[, [600, 650[ et [650, 700[.
Rien ne nous permet de dire le pourcentage des effectifs situés dans la classe [500, 550[.
Pour cela, on décide donc arbitrairement de répartir les 6, 95% dans les 4 différentes classes, soit
1/4×6, 95 = 1, 73% dans chacune des classes. On appellera ce nombre fréquence corrigée, notée fi corr. Cela nous donne donc le tableau suivant :
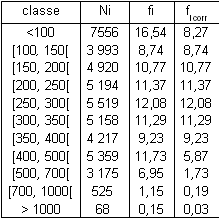
qui nous permet de tracer un graphique représentatif. Ce graphique est appelé un histogramme.
Pour les représentations graphiques de séries discrètes, le principe est le même.
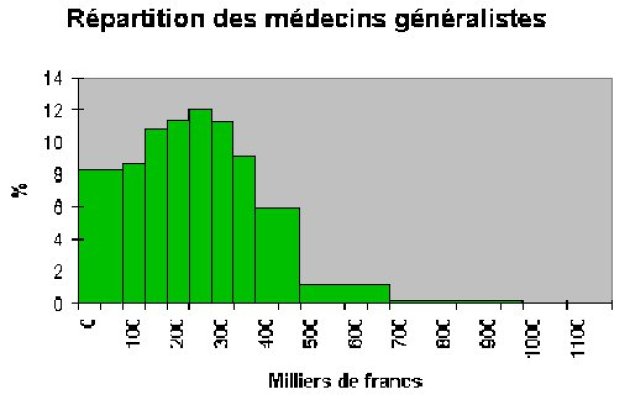
Ce principe fonctionne également pour la représentation de séries discrètes.
Boîtes à moustache (Box Plot)
Les logiciels que vous utiliserez proposent de nombreuses options destinées à impressionner votre auditoire grâce à de subtiles présentations graphiques. La boîte à moustaches est une de ces options les plus utilisées.
La définition varie légèrement selon les logiciels. Voici la définition proposée par Spad.
Pour chaque boîte, la ligne horizontale inférieure représente la valeur du premier quantile (ici 25%), la ligne horizontale supérieure représente la valeur du troisième quantile (ici 75%), la boîte grise représente donc 50% des individus.
La moyenne est représentée par un trait plein, la médiane par un trait discontinu.
Les limites des lignes verticales est variable : {maximum/minimum}, {1° décile/9° décile}, ... Vérifiez la documentation de votre logiciel.
Le point marqué d'une croix noire représente un individu dont la valeur est considérée comme extrême au sens de l'indice de TUKEY (Plus ou moins 1,5 fois la hauteur de la boîte grise).
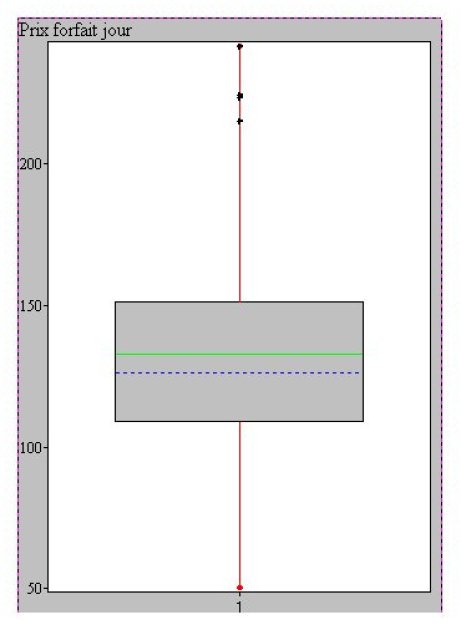
Un des intérêts des boîtes à moustaches peut être de comparer des populations entre elles. Par exemple, dans l'exemple suivant, on observe les boîtes à moustaches des prix des forfaits de remontées mécaniques des stations dans différentes régions de France.
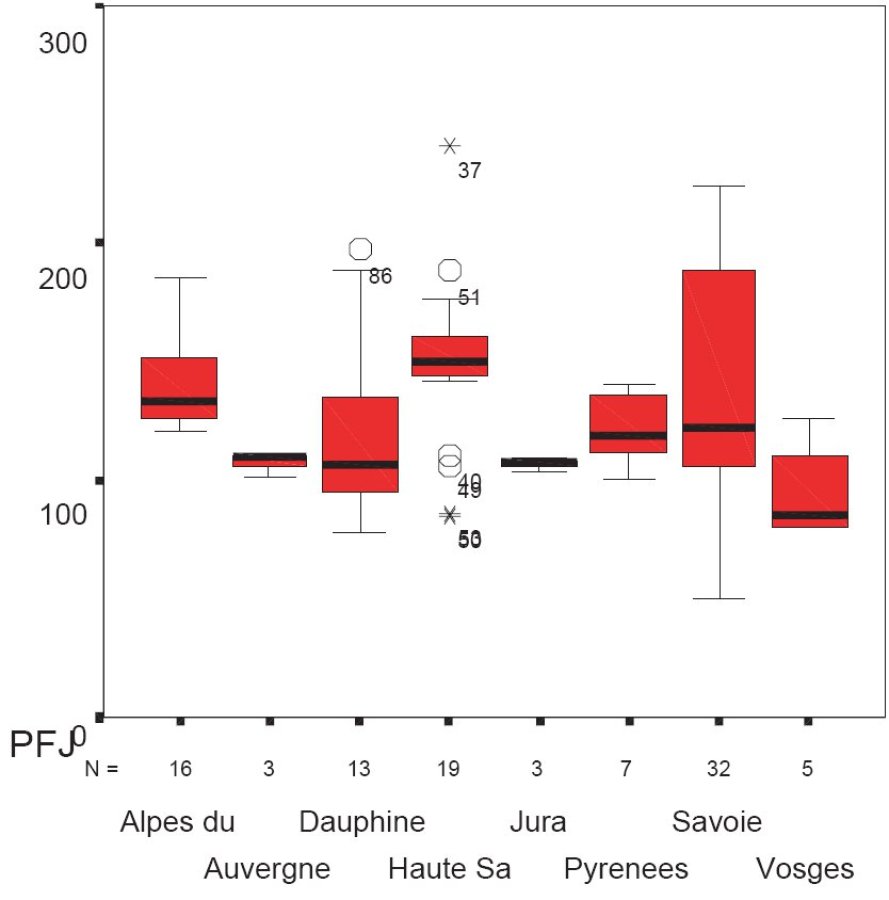
On peut observer sur cette figure que si l'on compare par exemple les PFJ en Haute Savoie et en Savoie, on trouve des prix plus homogènes et plus chers globalement en Haute Savoie qu'en Savoie. Est-ce que l'on vient de déceler des pratiques anti-concurrentielles ? Un cartel de la Haute-Savoie ? Ou est-ce autre chose ? Les données sont statistiques, leur interprétation vous en revient.



