
Distributions connues (loi normale, loi de Student, ...)
Après avoir étudié les différentes statistiques d'une variable quantitative (moyenne, médiane, quartile, écart-type, ...), nous pouvons nous rendre compte que cette variable a un comportement qui ressemble aux lois présentées par la théorie des probabilités. Ce paragraphe permettra de rappeler ou de préciser le comportement de quelques lois classiques et souvent utilisées en statistiques. Il n'est nullement nécessaire de connaître toutes les formules de ces lois, mais simplement de savoir les utiliser.
La seule définition à connaître est celle d'une densité.
Définition : Densité
On dit qu'une v.a. réelle X admet une densité p s'il existe une densité de probabilité P sur ![]() telle que pour tous réels a et b (a < b) on ait:
telle que pour tous réels a et b (a < b) on ait:
![]()
c'est à dire la probabilité que cette variable soit comprise entre a et b vaut l'intégrale entre a et b de cette densité p.
La notion de densité permet surtout de nous aider à comprendre de façon graphique le comportement d'une variable, comme on le verra par exemple pour la courbe connue de la gaussienne (courbe en cloche).
Mais ce n'est pas nécessaire pour l'instant de faire et comprendre tous les calculs.
Loi normale (ou loi Gaussienne, ou loi de Laplace)
C'est une loi que l'on rencontre très souvent dans la nature. Par exemple, la taille de l'être humain parmi une population suit une loi normale: beaucoup de personnes ont une taille proche de la moyenne et peu d'individus sont très petits ou très grands.
On dit que la variable U suit une loi normale centrée réduite si sa densité sur ![]() est définie par:
est définie par:
![]()
Si μ est un nombre réel et σ un nombre réel positif, on appelle densité gaussienne ou densité normale N (μ, σ) la densité sur ![]() définie par:
définie par:
![]()
Dans ces cas là, on note que la moyenne est μ (également appelée ici espérance) et l’écart type est σ.
Pour les différents calculs, on fait appel à des tables.
Prenons X une v.a. suivant une loi normale N (μ, σ). Nous aurons peut être besoin de calculer la probabilité que X prenne une valeur donnée dans un intervalle [a, b] (cela pourrait être la tranche de revenus de personnes ciblées par une vente, ou encore la gamme de pointure de chaussure que l'on veut conserver en stock).
Ainsi, ![]()
Pour calculer cette intégrale, on effectue le changement de variables ![]() .
.
Donc ![]()
avec ![]() .
.
Or, on se rend compte que la densité obtenue après le changement de variables est celle d'une loi normale centrée réduite.
Donc, si on pose U la v.a. telle que ![]() , U suit une loi normale centrée réduite N (0, 1) et
, U suit une loi normale centrée réduite N (0, 1) et
![]() .
.
Or, ces calculs d'intégrales ne sont toujours pas évidents à faire (il n'est pas conseillé au lecteur de chercher une primitive de la densité gaussienne). Aussi, pour résoudre ces calculs, il existe des tables de loi normale.
Le lecteur comprendra donc l'utilité de "normer" la loi (i.e. considérer U plutôt que X), car il ne peut exister de tables pour les lois normales quels que soient les paramètres.
Celles-ci donnent par exemple les valeurs de la fonction de répartition ![]() de la v.a. U suivant une loi normale centrée réduite ( @@@INSERER référence à la table), c'est à dire la fonction valant
de la v.a. U suivant une loi normale centrée réduite ( @@@INSERER référence à la table), c'est à dire la fonction valant
![]() .
.
Cette fonction de répartition vérifie les propriétés suivantes :
![]() (−u) = 1 −
(−u) = 1 −![]() (u)
(u)
![]() (0]=0,5
(0]=0,5
On a donc ![]() .
.
On se reportera à la table située en annexe (cf A.1) pour voir comment la lire, et comment effectuer les calculs.
Un autre cas possible de calcul est d'exprimer la déviation de la variable X par rapport à la moyenne μ en fonction des multiples de l'écart-type σ.
On a à calculer pour k > 0 :
![]() .
.
On remarquera dans les tables que P (−1, 96 < U < 1, 96) = 0, 95. Le nombre de 1, 96 est donc important car il permet de dire qu'à 5% d'erreur près, U se trouve dans l'intervalle [−1,96 ; 1,96].
De même, à 1% d'erreur près, U se trouve dans l'intervalle [−2,576 ; 2,576].
Il existe également des tables pour trouver ces nombres de 1,96 ou 2,576. Ces tables sont appelées table des fractiles (@@@INSERER REFERENCES).
On notera ![]() le fractile d'ordre
le fractile d'ordre ![]() , c'est à dire le nombre tel que
, c'est à dire le nombre tel que
![]() .
.
Le lecteur trouvera toutes ces tables en annexe.
De ces différents fractiles, on peut obtenir des renseignements importants.
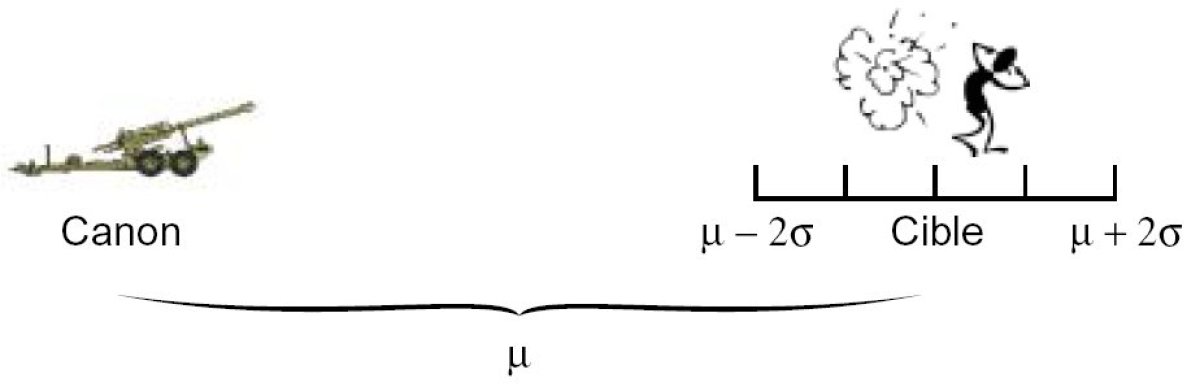
Supposons par exemple que la portée X d'un canon TRF1 suive une loi normale de paramètres μ = 24 km et σ = 25m.
Prenons X une v.a. suivant une loi normale N (μ, σ).
On a P (μ − 1, 96σ < X < μ+ 1, 96σ) = 0, 95.
On peut donc dire que 95% des tirs d'obus se trouveront dans un périmètre compris entre 24 km−50 m et 24 km+50 m.
Si l'on souhaite 99%, on utilise le fractile d'ordre 0,995, soit 2,57.
On a P (μ − 2, 57σ < X < μ+ 2, 57σ) = 0, 99.
On peut donc dire que 99% des tirs d'obus se trouveront dans un périmètre compris entre 24km−65m et 24km+65m.
On comprend donc tout l'intérêt de montrer qu'une variable aléatoire suit une loi normale.
Pour cela, il existe des tests de normalité, qui permettent à partir d'une série de mesure, de supposer ou non qu'une variable aléatoire suit une loi normale.
Loi du Khi-deux
Considérons ν variables aléatoires U1, U2, · · ·, Uv, indépendantes, et suivant chacune une loi normale centrée réduite N(0, 1). On appelle loi du khi-deux à ν degrés de liberté (ddl) la loi de la variable ![]() . On notera cette loi
. On notera cette loi ![]() .
.
Sa densité est la fonction définie par
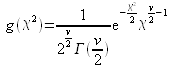 .
.
Dans certains ouvrages, on utilisera la notation anglo saxonne chi-deux.
Son espérance vaut ν et sa variance 2ν.
Comme pour la loi normale, on utilisera les tables figurant en annexe (cf A.4).
Loi de Student
Soit U une variable suivant une loi normale centrée réduite N(0, 1) , et X une loi du khi-deux à ν ddl (degrés de liberté), deux variables indépendantes entre elles. Soit la variable T définie par 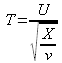 .
.
On dit que T suit une loi de Student à ν degrés de liberté.
Son espérance vaut 0 et sa variance ![]() .
.
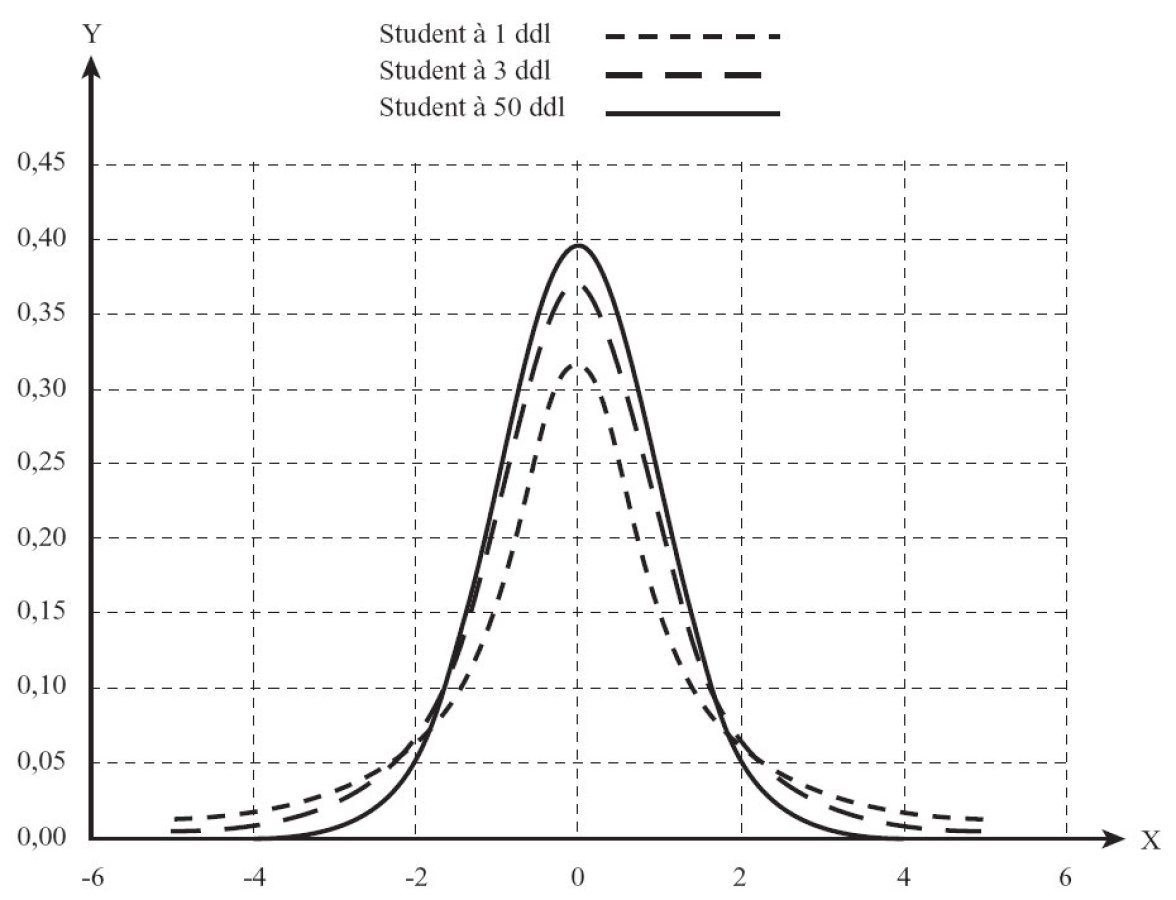
On remarquera que la loi de Student ressemble étrangement à la loi normale centrée réduite lorsque ν est grand.
En effet, lorsque ν est grand, la loi de Student peut se confondre avec une loi normale centrée réduite.
On utilisera également les tables situées en annexe (cf A.3).
Loi de Fisher Snedecor
Soient deux variables X1 et X2, indépendantes, et suivant respectivement des lois du khi-deux à ν1 et ν2 degrés de liberté. Alors la variable F définie par ![]()
suit une loi de Fisher-Snedecor à ν1 et ν2 degrés de liberté, et est notée F(ν1, ν2).
Son espérance vaut ![]() et sa variance
et sa variance ![]() pour ν2 assez grand.
pour ν2 assez grand.
Pour cette loi encore, on utilisera des tables.



