
Search for the first factor
Nous allons chercher le premier facteur F1.
Il s'agit de trouver la variable permettant de résumer au mieux l'information disponible grâce aux variables d'origine X1, X2, ...., Xp.
On la cherchera sous la forme
F1=u11 Z1 + u12 Z2 + ... + u1p Zp
où u11, u12, ..., u1p sont les coefficients cherchés de façon à conserver le maximum d'information.
On imposera à F1 d'être de moyenne 0 et d'écart type 1.
Le critère mathématique permettant à F1 d'être le plus en lien avec les variables d'origine est le suivant :
on cherchera à maximiser la corrélation entre F1 et les variables d'origine, c'est à dire qu'on cherche u11, u12, ..., u1p tels que :
R² (F1, X1) + R² (F1, X2) + ... + R² (F1,Xp) soit maximal
Mathématiquement, il est possible de maximiser ce critère.
Dans ce cas, R² (F1, X1) + R² (F1, X2) + ... + R²(F1,Xp) vaut la valeur λ1 (qui correspond à ce que l'on appelle en mathématique à la plus grande valeur propre, eigenvalue en anglais, de la matrice des corrélations R).
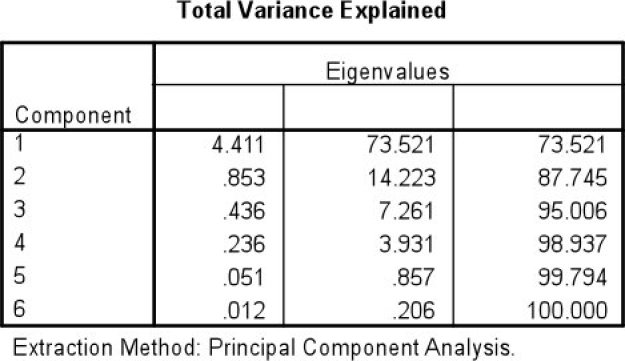
Dans notre exemple, λ1 vaut 4.411.
Les coefficients u11, u12, ..., u1p sont alors calculés comme étant les coordonnées du vecteur propre associé, eigenvector en anglais (de façon à ce que l'écart-type soit égal à 1).
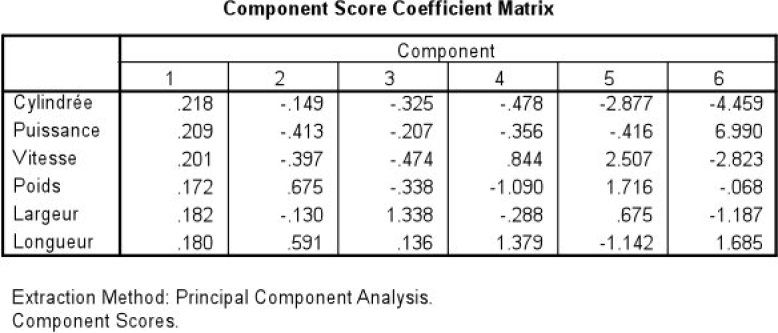
On a donc u11=0.128 ; u12=0.209 ; ... ; u1p=0.180.
On peut donc écrire F1 sous la forme
F1=0.218 Z cyl + 0.209 Z puis + 0.201 Z Vit + 0.172 Z poids + 0.182 Z Larg + 0.180 Z Long
F1 est une nouvelle variable permettant de résumer au mieux les variables d'origine.
On peut donc maintenant calculer les valeurs de F1 pour chacun des individus.
Par exemple,
F1 (Citroën C2) = 0.218 Z cyl (Citroën C2)+ 0.209 Z puis (Citroën C2)+ 0.201 Z Vit (Citroën C2)+ 0.172 Z poids (Citroën C2)+ 0.182 Z Larg (Citroën C2)+ 0.180 Z Long (Citroën C2)
donc
F1(Citroën C2) = 0.218 *(-1.054) + 0.209 * (-.935) + 0.201 * (-1.002) + 0.172 * (-1.431) + 0.182 * (-.812) + 0.180 * (-1. 052) = -1.210
Le tableau suivant permet d'avoir les coordonnées de F1 pour toutes les voitures.
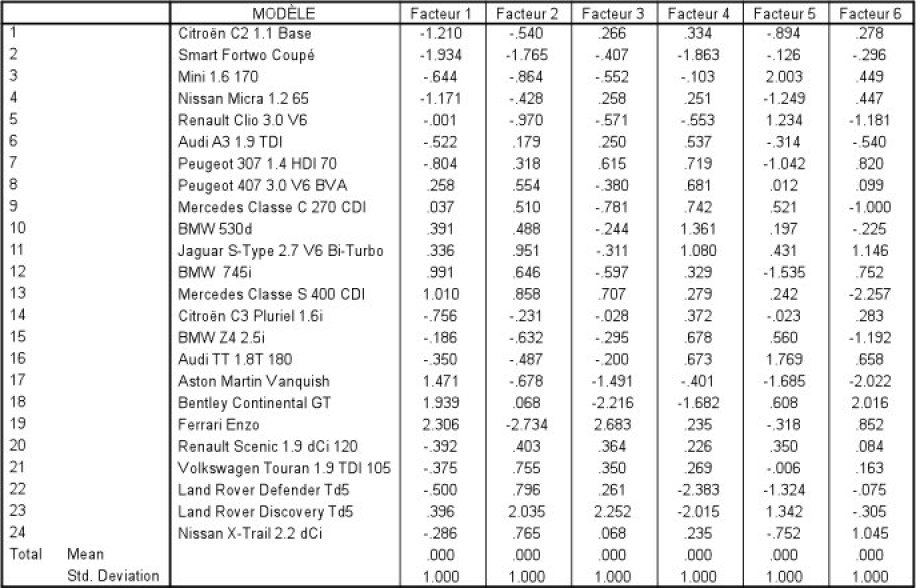
Le travail mathématique est effectué, à savoir la construction de ce facteur F1, nouvelle variable résumant les variables d'origine et leur étant le plus corrélé possible.
Reste maintenant le travail important du chargé d'étude, à savoir l'interprétation de ce facteur F1 et mesurer la pertinence de son utilisation.
Comment interpréter F1 ?
Il suffit simplement de se poser les questions suivante :
au vu de la construction de F1,
F1=0.218 Z cyl + 0.209 Z puis + 0.201 Z Vit + 0.172 Z poids + 0.182 Z Larg + 0.180 Z Long
quelles sont les variables qui vont faire en sorte que F1 soit le plus négatif possible pour un individu ?
Quelles sont les variables qui vont faire en sorte que F1 soit le plus positif possible pour un individu ?
Les réponses à ces deux questions permettront de donner un nom aux deux extrémités de l'axe qui représentera F1.

Essayons de répondre à la première question sur le coté négatif de F1.
Classons d'abord les variables par leur influence, mesurée par la valeur absolue de leur coefficient u1j.
Dans l'ordre, Zcyl, Zpuis, Zvit, Zlarg, Zlong, Zpoids (avec des coefficients ayant le même ordre de grandeur).
Donc, comme le coefficient de Zcyl est positif (+0.218), pour que F1 soit le plus négatif possible, cela signifie que que Zcyl doit être le plus négatif possible, c'est à dire que la Cylindrée doit être en dessous de la moyenne.
Ensuite, de la même façon, il faut que ZPuis soit négatif, ainsi que ZVit, ZLarg, ZLong et ZPoids, c'est à dire une puissance en dessous de la moyenne, une vitesse en dessous de la moyenne, et ainsi de suite.
En résumé, une voiture de Cylindrée en dessous de la moyenne, de Puissance en dessous de la moyenne, de Vitesse en dessous de la moyenne, de Largeur en dessous de la moyenne, de Longueur en dessous de la moyenne et de Poids en dessous de la moyenne sera sur le coté négatif de l'axe de F1.
Il s'agit maintenant de trouver un nom permettant de résumer toutes ces informations.
On pourra par exemple caractériser une voiture ayant un F1 négatif par le terme « petite voiture », petite ne se résumant pas à la taille de l'habitacle.
De la même façon, interprétons le coté positif de F1.
Si Zcyl, Zpuis, Zvit, Zlarg, Zlong et Zpoids sont tous positifs, F1 sera positif, c'est à dire si la voiture est de Cylindrée, de Puissance, de Vitesse, de Largeur, de Longueur et de Poids au dessus de la moyenne.
On pourra donc donner interpréter le coté positif de F1 par le terme « grosse voiture ».
Remarque : dans le cas particulier de cet exemple, du au fait que toutes les variables d'origine étaient très corrélées positivement entre elles, on se retrouve avec un premier facteur que l'on pourra appeler axe de taille. En effet, tous les coefficients de F1 sont du même signe et du même ordre de grandeur. L'interprétation s'en trouve donc facilitée.
Mais ce n'est pas toujours le cas.
Il reste maintenant à placer les coordonnées de toutes les voitures sur F1.
@@@@ Graph à construire
Étudions maintenant la pertinence de l'utilisation de F1 : que représente quantitativement F1 par rapport aux données d'origine ?
F1 a été construite de façon à maximiser le critère
R² (F1, X1) + R² (F1, X2) + ... + R² (F1,Xp)
Ce critère vaut au maximum 1+1+...+1 = p.
On pourra dire que plus R² (F1, X1) + R² (F1, X2) + ... + R² (F1,Xp) sera proche de p, meilleure sera la qualité de représentation de F1.
On pourra donc mesurer le pourcentage de l'information totale expliqué par la variable F1 par la quantité ( R²(F1, X1) + R² (F1, X2) + ... + R²(F1,Xp) )/p.
Or, on a vu par construction de F1 que R² (F1, X1) + R² (F1, X2) + ... + R² (F1,Xp) = λ1, plus grande valeur propre de la matrice de corrélation R.
Le pourcentage de l'information totale expliqué par F1 vaut donc λ1/p.
ce qui vaut dans notre exemple 4.411 / 6 soit 73.521%.
On peut donc dire que F1 explique à elle seule 73.521% de l'information donnée grâce aux p variables initiales X1, X2, ..., Xp.
Si on avait choisi une variable aléatoirement, sans utiliser la méthode expliquée auparavant, on était en droit d'attendre un pourcentage d'information de une variable parmi p, soit 1/p (1/6 = 16% dans notre exemple).
Or, grâce à cette méthode, on optimise le résumé et on trouve lambda1/p (73% dans notre exemple).
Bien évidemment, plus les variables sont corrélées à l'origine, meilleur sera ce résultat, ce qui se comprend intuitivement mais aussi mathématiquement.



