
The problem
Avec les possibilités accrues de recueil de données, nous nous retrouvons souvent dans la situation de surabondance d'information.
Le mot « data mining » fait référence aux chercheurs d'or qui passaient ce qu'ils trouvaient dans les ruisseaux dans un tamis, afin d'en extraire la pépite d'or au milieu de vulgaires cailloux.
L'objectif de l'analyse factorielle sera similaire. Comment simplifier un jeu de données souvent complexe afin d'en comprendre la substance ?
Comment appréhender un jeu de données avec n individus et p variables, n et p prenant souvent des valeurs élevées ?
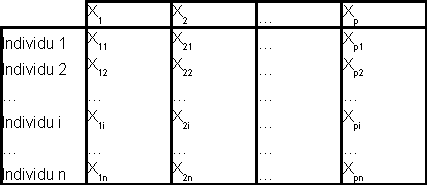
L'analyse factorielle a pour objectif de résumer les variables d'origine en en créant de nouvelles, appelées facteurs, qui auront l'avantage d'être moins nombreuses et souvent plus explicites car agglomérant les précédentes.
Pour illustrer ceci, prenant un exemple lié à la météorologie.

Nous pouvons nous trouver en présence de multiples variables (température, pression, hygrométrie, direction du vent, force des vents, etc, etc).
Or ce qui va souvent nous intéresser est un résumé de toutes ces variables : quel temps va-t-il faire demain ?
On peut également avoir une approche géométrique pour illustrer l'analyse factorielle (approche liée à l'analyse en composantes principales, ACP).
Comme on effectue un nuage de points lorsque nous sommes en présence de deux variables (l'une en abscisse, l'autre en ordonnées), imaginons que l'on crée un axe pour chacune des variables d'origine. Il y aura donc p axes. Plaçons maintenant les n individus dans cet espace à p dimensions.
C'est bien évidemment complexe à imaginer. L'objectif de la méthode est de projeter ce nuage de points sur un plan (espace à 2 dimensions) permettant de résumer le mieux possible l'information.
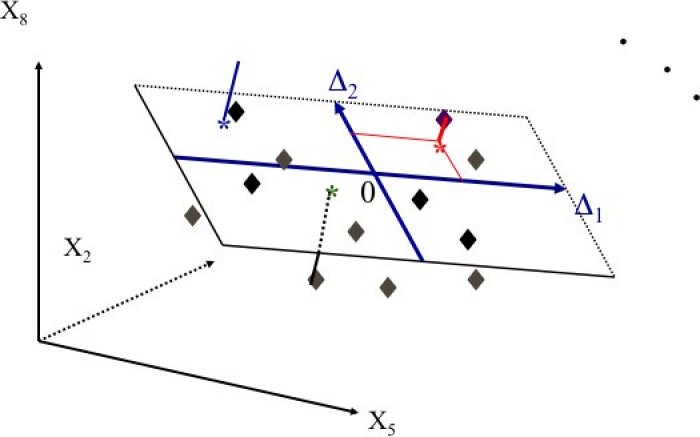
Cette approche géométrique montre bien que l'on perdra forcément de l'information en la résumant, l'objectif étant d'en perdre le moins possible, c'est à dire être le plus proche possible de la réalité d'origine.
Pour présenter l'analyse factorielle, nous allons étudier le cas Autos2004.
Il s'agit de 24 voitures dont on a mesuré les caractéristiques pour 6 variables
X1=Cylindrée
X2=Puissance
X3=Vitesse
X4=Poids
X5=Largeur
X6=Longueur
Dans un premier temps, et comme le but de la méthode est de combiner des variables entre elles ayant pourtant des unités et des ordres de grandeur différents, on va « standardiser » ces variables, c'est à dire les remplacer par les variables
Zj=(Xj – moyenne Xj) / écart type de Xj
ce qui donne le jeu de données suivant :
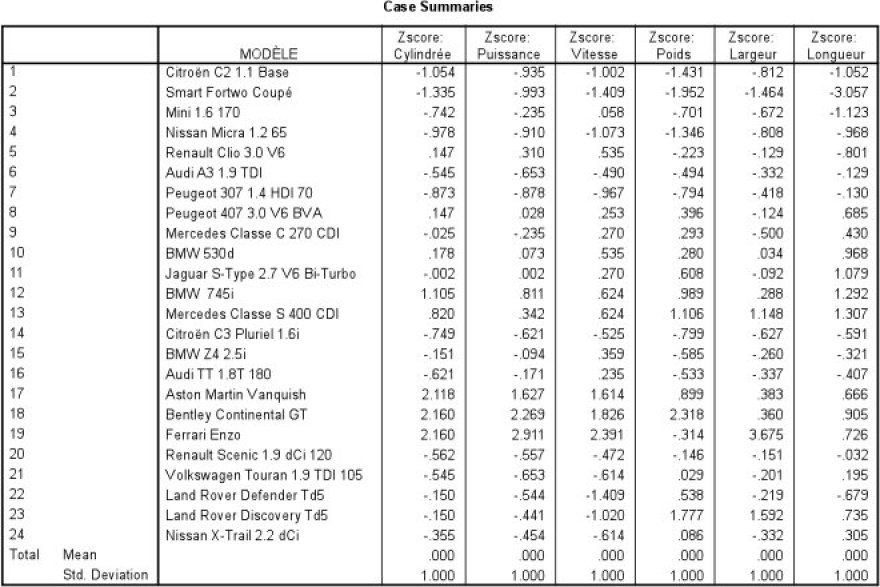
Le premier avantage est de pouvoir identifier les individus i (voitures) prenant des valeurs extrêmes pour telle ou telle variable (Zj(i) < -2 ou Zj(i) >2), par exemple la cylindrée de l'Aston Martin ou la la longueur de la Smart Fortwo coupé.
Dans un deuxième temps, nous allons regarder les corrélations deux à deux entre ces variables.
Pour cela, nous construisons la matrice des corrélations, que l'on nommera R, et qui recense dans un même tableau ces corrélations.
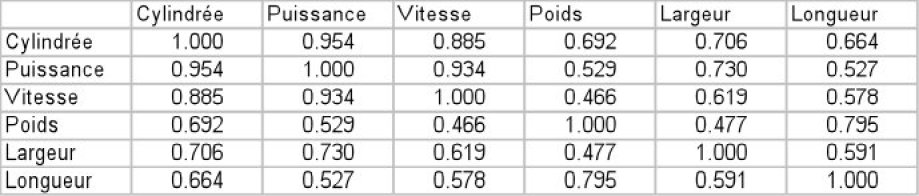
On observe bien évidemment des 1 sur la diagonale de cette matrice.
On voit également que ce tableau est symétrique, en effet, la corrélation R(Puissance, Cylindrée) = R(Cylindrée, Puissance) = 0,954.
Ensuite, il faut tester si ces corrélations sont significatives ou pas. Pour cela, comme on peut le voir par ailleurs (cf corrélation, régression), on compare les valeurs absolues de R à ![]() .
.
Dans cet exemple, n=24, ![]() = 0,41.
= 0,41.
Nous pouvons donc observer qu'une grande partie des corrélations sont significatives.
Cette observation est un pré requis à l'analyse factorielle. En effet, l'objectif étant de résumer les variables entre elles, cela sera forcément plus facile si les variables sont corrélées et non indépendantes.



