
Overall quality of the model
La formule de décomposition totale, explicitée en régression simple est toujours valable, à savoir ![]() .
.
La démonstration est un peu plus complexe et ne sera pas présentée.
Par conséquent, et comme en régression simple, on peut introduire le coefficient de détermination 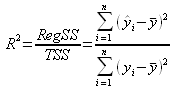

On peut donc dire que 80,9 % du prix du forfait est expliqué grâce à ce modèle.
Par contre, et c'est une grande différence avec la régression simple, le coefficient de corrélation R n'a plus ici aucune signification. Il était valable et intéressant lorsque seulement deux variables étaient dans le modèle, une étant dépendante de l'autre, et mesurait le comportement simultané de ces deux variables.
Pour tester la qualité du modèle, on utilisera donc un autre test et une autre statistique, à savoir le F de Fischer Snedecor.
Les hypothèses du test sont :
H0 : « Y ne dépend d'aucune des variables X1, X2, ..., Xk »
H1 : « Y dépend d'au moins une des variables Xj »
La statistique utilisée est ![]()
La règle de décision est qu'on rejette H0 au profit de H1 avec un risque d'erreur alpha lorsque![]() (fractile d'une loi de Fischer Snedecor à k et n-k-1 degrés de liberté, où k est le nombre de variables explicatives dans le modèle).
(fractile d'une loi de Fischer Snedecor à k et n-k-1 degrés de liberté, où k est le nombre de variables explicatives dans le modèle).
Bien évidemment et comme dans beaucoup de tests, on regardera directement le niveau de signification qui correspond au risque d'erreur lorsqu'on rejette H0.
Dans notre exemple, F=54,365 et le niveau de signification du test (Sig) est inférieur à 0,1%, ce qui permet de rejeter le fait qu'aucune des variables Xj n'a d'influence sur Y.
On peut donc raisonnablement imaginer que notre modèles est globalement pertinent.
@@@@@ rajouter un topo sur le R2 ajusté
Il faut maintenant se poser la question de la précision du modèle.
Et comme en régression multiple, et grâce à la méthode des moindres carrés, si on peut écrire le modèle sous la forme
![]() =b0+b1X1+b2X2+...+bkXk ,
=b0+b1X1+b2X2+...+bkXk ,
on peut aussi écrire que
Y = b0+b1X1+b2X2 + ... + bkXk + terme résiduel,
ce terme résiduel étant une variable suivant une loi normale d'espérance nulle et d'écart-type ![]() .
.
Pour estimer ![]() , on utilisera encore les valeurs de ei connues, mais avec l'estimation suivante :
, on utilisera encore les valeurs de ei connues, mais avec l'estimation suivante :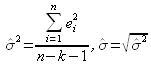
Cette valeur, toujours appelée dans le logiciel SPSS standard error of the estimate, est de 17,237.
De la même façon qu'en régression simple, on peut utiliser le modèle afin d'avoir une estimation sous la forme d'un intervalle de prévision ![]() .
.
Le modèle obtenu en régression multiple a donc une précision de 2![]() = 2x17,237=34,5FF à comparer avec la précision de 50 FF du modèle de régression simple.
= 2x17,237=34,5FF à comparer avec la précision de 50 FF du modèle de régression simple.
Il y a donc une amélioration significative à utiliser la régression multiple en rajoutant d'autres variables comme prédicteurs.



