
Classification hiérarchique
Les méthodes hiérarchiques de classification permettent de regrouper à chaque étape les individus entre eux et de choisir ensuite le nombre de groupes qui conviendra le mieux.
Nous allons décrire l'algorithme de la classification ascendante hiérarchique avec la méthode de Ward.
Au tout début, on considère qu'il y a autant de groupes que d'individus, à savoir n.
A la première étape, on mesure toutes les distances entre tous les individus afin d'identifier les deux individus les plus proches. On décide de les regrouper en un groupe de deux individus.
Puis à chaque étape, on mesure les distances entre tous les groupes (qu'ils soient constitués d'un ou plusieurs individus) afin de regrouper les deux groupes les plus proches.
Attardons-nous un instant sur cette notion de distance entre individus ou entre groupes.
N'oublions pas que les individus sont caractérisés par p variables.
Afin de pouvoir mettre en place la distance euclidienne classique dans cet espace à p dimensions, il faut nécessairement que les variables soient avec le même ordre de grandeur ou la même unité.
C'est pourquoi on effectuera la classification sur les données standardisées, à savoir les Z values.
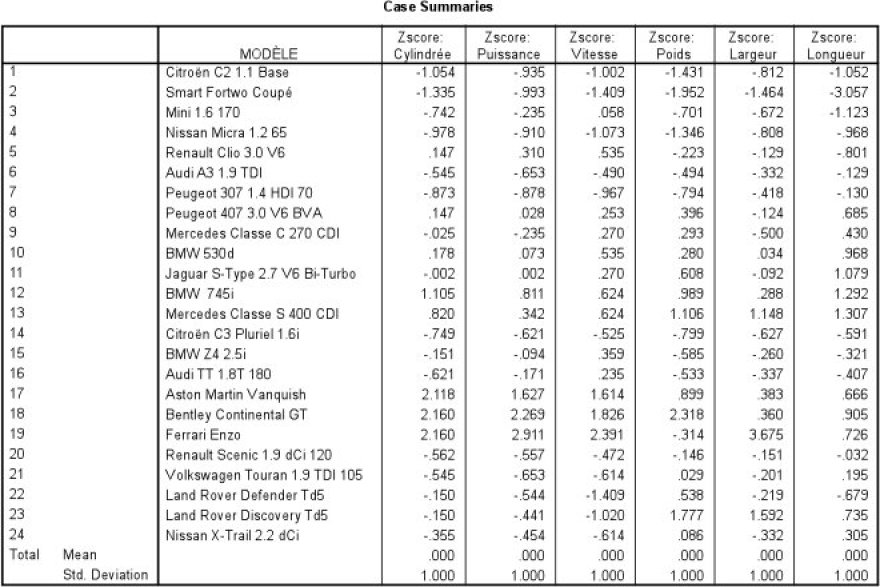
Prenons l'exemple « autos2004 », nous travaillerons donc sur les p Z score pour les n=24 individus :
Il s'agit maintenant de définir une distance entre groupes.
On utilisera la distance de Ward
 Distance de Ward |
ni=number of cases in cluster Gi |
c'est à dire que la distance entre deux groupes est la distance entre leurs centres de gravité pondérée par le produit du nombre d'individus dans chaque groupe divisé par leur somme.
On peut donc montrer qu'à la première étape de la classification sur notre exemple, la distance de Ward entre la citroën C2 et la Nissan Mica vaut ![]() .
.
L'algorithme se déroule donc pas à pas, jusqu'à ce que tous les individus soient regroupés en un seul et unique groupe.
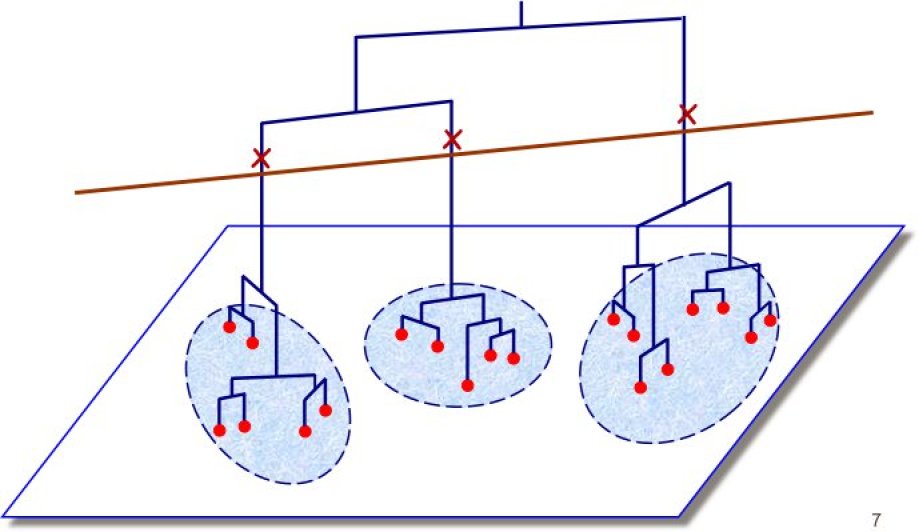
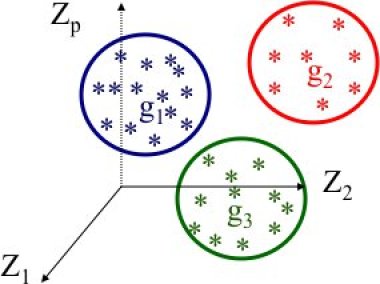
Il faut maintenant choisir un moment où on arrête l'algorithme, ce qui définira le nombre de groupes et leurs compositions (3 groupes dans l'illustration).
On peut remarquer que l'agglomération pas à pas en groupes fait apparaître un graphique en forme d'arbre.
On utilisera ce graphique appelé dendrogramme pour choisir le niveau où on effectuera la partition et définir ainsi le nombre de groupes.
@@@@ graphique à refaire
Reste maintenant à mesurer la qualité de la partition choisie.
En effet, à chaque fois que l'on regroupe des individus ou des groupes, on perd de l'information initiale.
Pour mesurer cette perte d'information, on utilise la formule suivante :
![]()
Cette formule décompose la somme des carrés totale (distance entre les individus d'origine et le centre de gravité g, quantité constante et ne dépendant pas de la partition) en la somme de la somme des carrés inter-classes qui correspond à la somme des distances des centres de gravité de chaque groupe au centre de gravité du nuage et la somme des somme des carrés intra-classes qui correspond à la somme des distances de chaque individu au centre de gravité de son groupe.
A l'état initial de la classification (quand chaque individu est un groupe), la somme des carrés inter-classes est égale à la somme des carrés totale tandis que la somme des carrés intra-classes est nulle.
A la fin de la classification (quand tous les individus sont regroupés en un groupe), la somme des carrés inter-classes est nulle alors que la somme des carrés intra-classes est maximale et égale à la somme des carrés totale.
On cherchera donc à mesurer à chaque étape la perte de somme des carrés inter-classes ce qui correspond à la perte d'information à chaque regroupement.
C'est cette donnée qui figure en abscisse du dendrogramme.
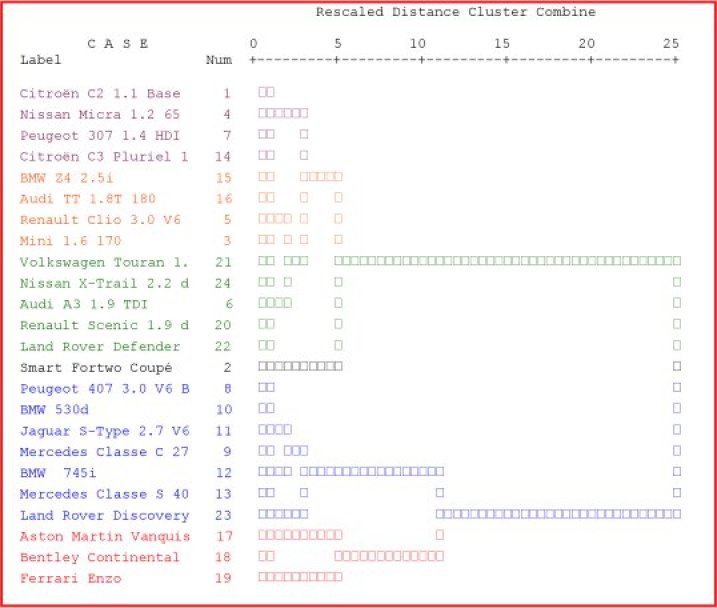
Ces quantités peuvent se retrouver sur le résumé
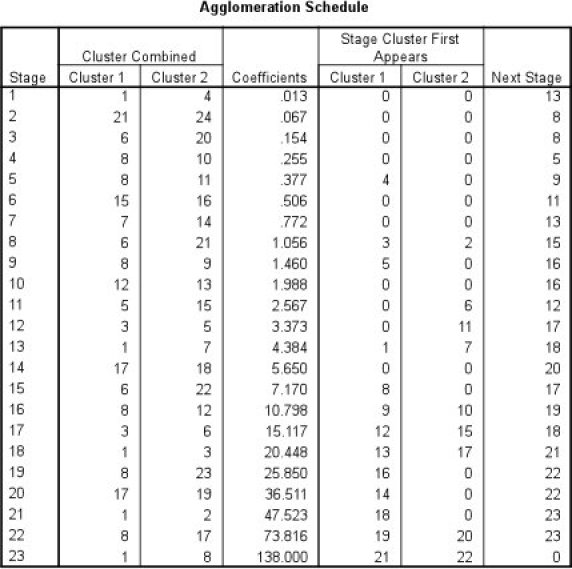
La colonne coefficient donne la somme des carrés intra-classes après chaque étape de la classification.
La dernière ligne correspond à la dernière étape, à savoir le regroupement en un unique groupe.
Par conséquent, on y retrouve la somme des carrés intra-classes finale qui est la somme des carrés totale.
Dans l'exemple, nous avons donc une somme des carrés totale égale à 138.
Pour mesurer la qualité de la partition en k groupes, on mesurera le rapport entre la somme des carrés inter-classes et la somme des carrés totale.
Le tableau ne donne pas la somme des carrés inter-classes mais la somme des carrés intra-classes.
Il suffit de calculer la somme des carrés totale – somme des carrés intra-classes.
Par exemple, pour une partition en 2 groupes, cela correspond à l'avant-dernière ligne (étape n-2).
Dans l'exemple, somme des carrés inter-classes en 2 groupes = somme des carrés totale – somme des carrés intra-classes en 2 groupes = 138 – 73.816 = 64.184
Par conséquent, la qualité d'information conservée par un regroupement en 2 groupes est égale à
somme des carrés inter-classes en 2 groupes / somme des carrés totale = 64.184 / 138 = 46.5 %.
On peut donc dire qu'en considérant une partition en 2 groupes, on a conservé 46.5 % de l'information comprise dans les données d'origine.
Mesurons maintenant la qualité de représentation d'une partition en k groupes.
Le coefficient se trouve à l'étape n-k :
somme des carrés inter-classes en k groupes = somme des carrés totale – somme des carrés intra-classes en k groupes.
Dans notre exemple, si on cherche à mesurer la qualité d'une partition en 5 groupes, la somme des carrés intra-classes en 5 groupes = 25.850.
Donc la somme des carrés inter-classes en 5 groupes = 138 – 25.850 = 112.15.
Par conséquent, la qualité d'information conservée par un regroupement en 5 groupes est égale à
somme des carrés inter-classes en 5 groupes / somme des carrés totale = 112.15 / 138 = 81.2%.
On peut donc dire qu'en considérant une partition en 5 groupes, on a conservé plus de 80 % de l'information comprise dans les données d'origine, ce qui est assez conséquent.
La question à se poser est maintenant de savoir où effectuer la partition, c'est à dire combien de groupes étudier ?
Bien évidemment, plus il y de groupes, meilleure sera la qualité de représentation, mais moins l'effet cherché de regrouper les individus est obtenu.
De plus, plus il y a de groupes et plus ils seront nombreux à interpréter ensuite.
Il faut donc trouver le bon compromis entre le gain de regrouper une étape supplémentaire et la perte d'information.
Dans notre exemple, on choisira par exemple 5 groupes (qualité conservée de 81.2 %) mais pas 6 groupes (qualité de 85.2 %).
En effet, cela ne vaut pas la peine de conserver 6 groupes par rapport à 5 pour un gain de qualité d'à peine 4%.



