
Apport marginal de chacune des variables
Néanmoins, le fait de ne pas se poser de questions a priori sur les variables que l'on utilise comme prédicteurs peut poser un certain nombre de problèmes et entrainer différentes questions.
Reprenons le modèle obtenu dans l'exemple ski99 :
![]() = 52.6459 + 0.4302PIS - 0.002AST -0.0111REM + 0.0189API + -0.0740KMF + 0.0016LIT - 0.0371HOT
= 52.6459 + 0.4302PIS - 0.002AST -0.0111REM + 0.0189API + -0.0740KMF + 0.0016LIT - 0.0371HOT
1) Peut-on dire que la variable nombre de pistes (PIS) est la plus influente dans le modèle pour expliquer le prix du forfait (PFJ) de par son coefficient bPIS le plus élevé en valeur absolue (0,430) ?
2) Peut-on dire que plus il y a de remontées mécaniques (REM) , plus le prix (PFJ) sera bas de par le signe négatif de son coefficient (bREM = - 0,0111) ?
3) N'y a-t-il pas des variables qui n'ont rien à faire pour expliquer le prix du forfait ?
4) N'y a-t-il pas une certaine confusion avec des variables présentant le même type d'information comme altitude des pistes (API) et altitude de la station (AST) ou nombre de pistes (PIS) et nombre de remontées (REM) ou encore nombre de lits (LIT) et nombre d'hôtels (HOT), c'est à dire avec des variables qui peuvent apparaître corrélées entre elles (ce qui est corroboré par la matrice des corrélations @@@@@ A FAIRE en SPSS ) ?
Toutes ces questions, légitimes, doivent être posées avant de proposer un modèle.
Car l'utilisateur aura vite fait de proposer des conclusions hâtives à la vue des coefficients qui ne sont peut être pas du tout pertinentes, et même totalement fausses.
Tout d'abord, et pour répondre à la première question sur la valeur absolue du coefficient, dire que la variable la plus influente est celle dont le coefficient est le plus élevé est totalement absurde.
En effet, la valeur du coefficient dépend de la variable et surtout de son unité.
Imaginons qu'on convertisse la variable altitude station, en mètres dans notre exemple, pour la transformer en kilomètres ou en millimètres, le coefficient s'en trouverait divisé ou multiplié par mille naturellement. Et pourtant, cela ne changerait pas l'influence de cette variable dans le modèle.
Pour mesurer le poids de chaque variable, on va donc «normer » le coefficient en le divisant par une sorte d' écart-type.
On introduit donc le coefficient tj=bj/sj
où 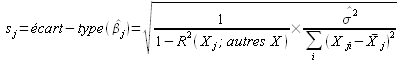
De part l'introduction de ce coefficient, on pourra se poser la question de l'influence réelle de la variable Xj comme prédicteur dans ce modèle (c'est à dire en présence des autres variables).
Pour cela, nous allons utiliser le test suivant :
H0 : la variable Xj n'a pas une influence significative dans ce modèle
H1 : la variable Xj a une influence significative dans ce modèle
On utilisera tj comme statistique.
La règle de décision est :
on rejette H0 au profit de H1 avec un risque d'errreur α si ![]() (fractile d'une loi de Student à n-k-1 degrés de liberté).
(fractile d'une loi de Student à n-k-1 degrés de liberté).
Et comme pour tout test, on utilisera le niveau de signification du test (noté Sig dans SPSS).
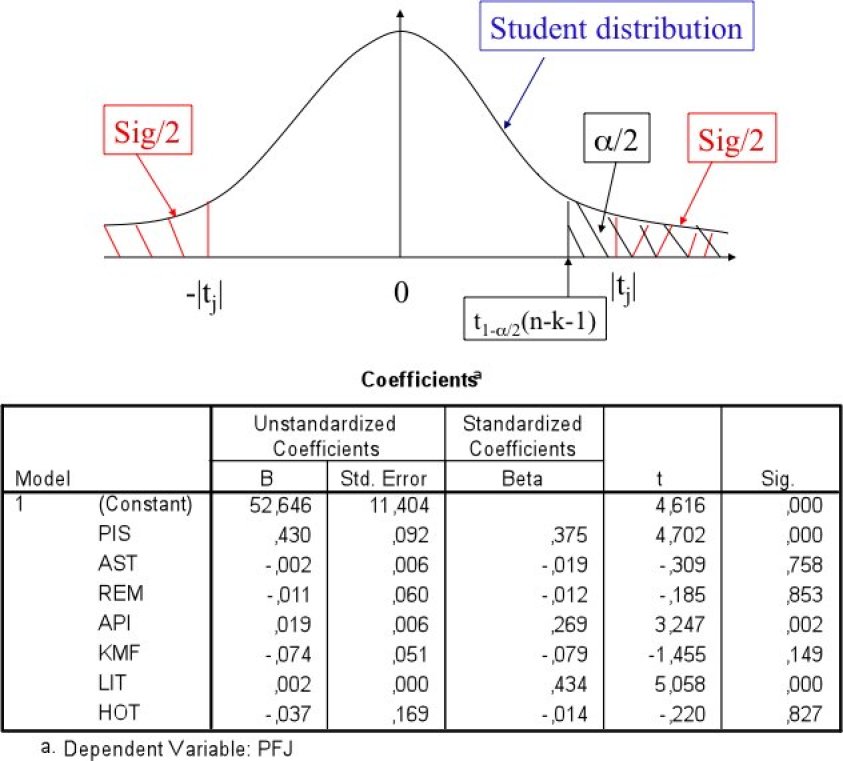
On peut donc comparer les tj au fractile d'une loi de Student à n-k-1 degrés de liberté c'est à dire 98-7-1=90 degrés de liberté, qui a pour valeur 1,987.
On peut donc voir que les variables significatives dans ce modèle sont PIS (tPIS=4,702), API (tAPI=3,247) et LIT (tLIT=5,058).
On pouvait également regarder les niveaux de signification (Sig) et dire que si par exemple on considère que la variable AST a de l'influence dans ce modèle (et que donc plus la station est élevée, plus le prix sera bas de par le coefficient négatif de la variable), on a un risque d'erreur de 75,8% (SigAST=0,758).
Attention, cela ne signifie pas que l'altitude de la station n'a pas d'importance pour expliquer le prix du forfait. Mais dans ce modèle, c'est à dire en présence des autres variables, elle n'aura pas d'influence.
On peut imaginer par exemple que si l'on n'avait pas mis la variable Altitude des pistes (API), AST aurait eu dans ce cas une réelle influence.
@@@@ faire la simulation dans SPSS.
En conclusion, ce modèle est donc bon globalement (vérifié par le R2 et le F de Fischer), a une bonne précision par rapport au modèle de régression simple, mais il ne faut pas tirer de conclusions sur les signes des coefficients de AST, REM, KMF et HOT et sur leur influence dans ce modèle.



